

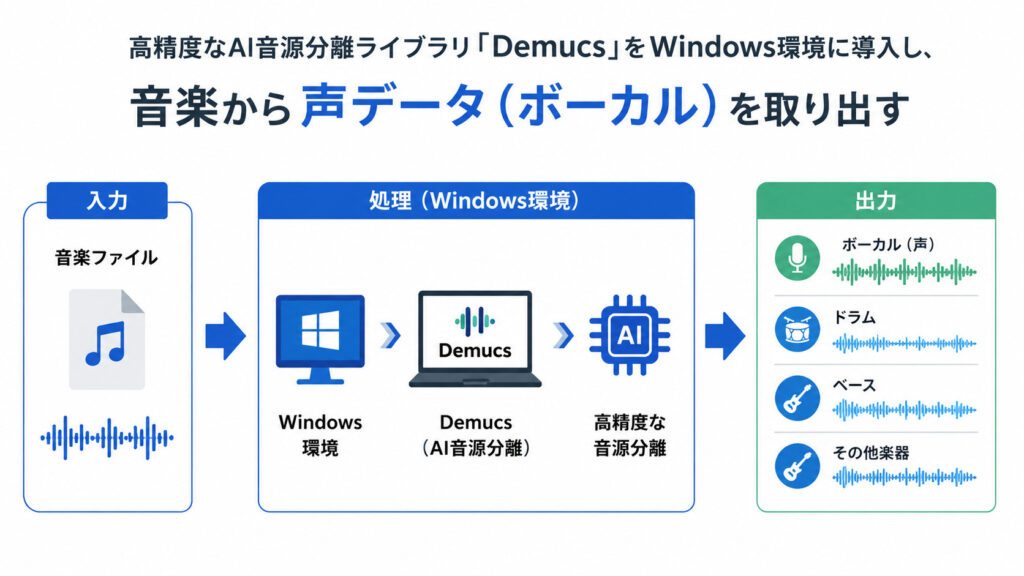
こんにちは。今回は、高精度なAI音源分離ライブラリ「Demucs」をWindows環境に導入し、音楽から声データ(ボーカル)を取り出すための最短手順をまとめました。GPUを活用して高速な変換環境を構築しましょう。
1. 仮想環境(venv)の用意
Pythonのプロジェクトごとに環境を分離するため、仮想環境を作成して有効化します。
python -m venv venv
venv\Scripts\activate2. PyTorch(CUDA 12.1対応版)のインストール
GPU(NVIDIA製グラボ)を使用して計算を高速化するため、適切なCUDAバージョンのPyTorchをインストールします。
pip install torch==2.5.1+cu121 torchaudio==2.5.1+cu121 ^
--index-url https://download.pytorch.org/whl/cu1213. Demucsのインストール
最後に、音源分離の本体であるDemucsをインストールします。
pip install demucs4. 音声分離を実行する
準備ができたら、音声ファイルを指定して分離を開始します。デフォルトでは4つのパート(ボーカル、ドラム、ベース、その他)に分割されます。
# 基本的な実行方法
demucs sample.mp3
# ボーカルと伴奏の2つだけに分ける場合
demucs --two-stems=vocals sample.mp3※実行後、separated フォルダの中に出力された音声ファイルが保存されます。mp3ファイルを扱う場合は、別途 ffmpeg がパスに通っている必要がありますのでご注意ください。