プログラミングにおいて、文字列の検索や置換は日常的に行う作業ですよね。例えば、ある特定の単語が含まれているかを確認したり、メールアドレスの形式が正しいかをチェックしたり、ログファイルから特定の情報を抽出したり……。Pythonには標準で強力な文字列操作メソッドが用意されていますが、もっと複雑なパターンを持つ文字列を扱いたい場合に活躍するのが、「正規表現」です。そして、Pythonで正規表現を扱うための標準ライブラリが、今回ご紹介するreモジュールです。
概要
reモジュールは、Regular Expression(正規表現)を利用して、文字列のパターンマッチング、検索、置換、分割などの高度な処理を行うためのPython標準ライブラリです。正規表現とは、特定のパターンを記述するための特殊な文字列のことで、これを使うことで非常に柔軟かつ強力な文字列操作が可能になります。
正規表現は最初は難しく感じるかもしれませんが、一度覚えるととっても便利なんです!私も最初は戸惑いましたけど、今では大活躍しています。
例えば、以下のような処理をスマートに実現できます。
- 特定の形式のメールアドレスや電話番号を抽出する
- HTMLタグを一括で除去する
- ログファイルから日付やエラーメッセージだけを抜き出す
- ユーザーが入力したデータが特定の形式に沿っているか検証する
reモジュールには、re.search(), re.match(), re.findall(), re.sub()など、目的に応じて様々な便利な関数が用意されています。
メリット
reモジュールと正規表現を使うことには、いくつかの大きなメリットがあります。
- 強力なパターンマッチング: 複雑な条件や曖昧なパターンで文字列を検索・抽出する際に、非常に強力な表現力を発揮します。Pythonの通常の文字列メソッドでは難しいようなパターンも、正規表現なら簡潔に記述できます。
- コードの簡潔化: 多くの
if文やループを組み合わせることで実現できるような文字列処理も、正規表現一つでスマートに表現できます。これにより、コードの可読性やメンテナンス性が向上します。 - 汎用的な知識: 正規表現の記述方法は、Pythonに限らず、Perl, JavaScript, Javaなどの他のプログラミング言語や、テキストエディタ、コマンドラインツール(grepなど)でも共通して使われることが多いため、一度習得すれば幅広い場面で活用できるスキルとなります。
サンプルコード
それでは、実際にreモジュールの主要な関数を使って、どのようなことができるのか見ていきましょう。
re.search(): パターンを検索し、最初に見つかったマッチオブジェクトを返す
re.search()は、文字列全体から指定したパターンを検索し、最初に見つかった一致箇所をMatchオブジェクトとして返します。見つからなかった場合はNoneを返します。
import re
text = "私の好きな数字は123と456です。"
pattern = r"\d+" # 1回以上の数字にマッチするパターン
match = re.search(pattern, text)
if match:
print(f"マッチした文字列: {match.group()}") # マッチした部分文字列
print(f"開始位置: {match.start()}")
print(f"終了位置: {match.end()}")
else:
print("パターンは見つかりませんでした。")re.findall(): パターンに一致する全ての部分文字列をリストとして返す
re.findall()は、文字列内で指定したパターンに一致する全ての部分文字列を、リスト形式で返します。
import re
text = "電話番号は090-1234-5678、郵便番号は123-4567です。"
pattern = r"\d{3}-\d{4}" # 3桁-4桁の数字にマッチするパターン
numbers = re.findall(pattern, text)
print(f"見つかった番号: {numbers}")
text_email = "お問い合わせは info@example.com または support@sample.co.jp まで。"
pattern_email = r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}" # メールアドレスのパターン
emails = re.findall(pattern_email, text_email)
print(f"見つかったメールアドレス: {emails}")re.sub(): パターンに一致する部分を別の文字列に置換する
re.sub()は、文字列内で指定したパターンに一致する全ての部分を、別の文字列に置換します。
import re
text_html = "<h1>タイトル</h1><p>これはテストです。</p>"
# HTMLタグを空文字列に置換するパターン
pattern_tag = r"<[^>]*>"
cleaned_text = re.sub(pattern_tag, "", text_html)
print(f"HTMLタグを除去した文字列: {cleaned_text}")
text_phone = "私の電話番号は 090-1234-5678 です。"
# 電話番号の間にハイフンを追加する(すでにハイフンがある場合も考慮)
# グループ化と参照機能を使う
pattern_phone = r"(\d{3})(\d{4})(\d{4})"
formatted_phone = re.sub(pattern_phone, r"\1-\2-\3", "09012345678")
print(f"書式化した電話番号: {formatted_phone}")
いかがでしたでしょうか?reモジュールを使うと、こんなにスマートに文字列処理ができるんですよ!使いこなせるようになると、プログラミングがもっと楽しくなりますね!
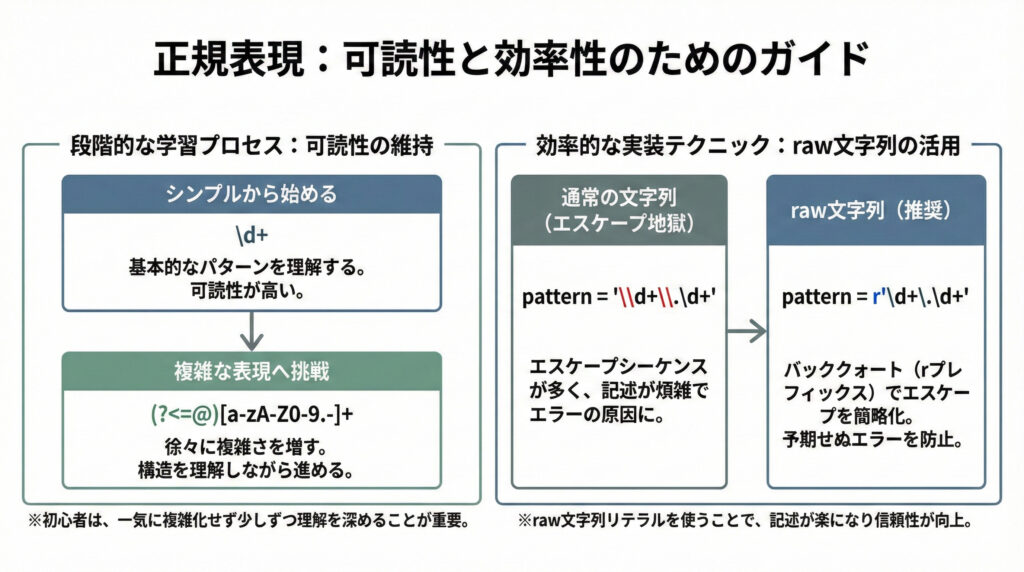
みーちゃんのワンポイント
正規表現は強力なツールですが、パターンが複雑になると可読性が低下しやすいです。特に初心者の方は、まずはシンプルなパターンから試して、少しずつ複雑な表現に挑戦するのがおすすめです。 また、正規表現パターンを定義する際は、バッククォート(rプレフィックス)を使ってraw文字列リテラルとして扱うと、エスケープシーケンスの記述が楽になり、予期せぬエラーを防ぐことができますよ。