Pythonでデータ処理といえば、Pandasが定番ですよね。私も普段から大変お世話になっています。ですが、最近データ量の増加や処理速度の課題に直面することはありませんか?そんな時にぜひ知ってほしいのが、今回ご紹介する新世代の高速DataFrameライブラリ、Polarsです。今回は、Polarsの魅力と基本的な使い方について、一緒に学んでいきましょう!
概要
Polarsは、Rust言語で書かれたPythonのDataFrameライブラリです。Pandasと同様に表形式データを効率的に扱うことができますが、その内部実装は大きく異なります。特に、並列処理やLazy Evaluation(遅延評価)といった特徴により、大規模なデータセットに対しても驚異的なパフォーマンスを発揮します。
メリット
Polarsを導入することで、以下のような多くのメリットを享受できます。
- 圧倒的な処理速度: Rustによる高速なバックエンドと、効率的な並列処理、そしてクエリ最適化を実現するLazy Evaluationのおかげで、Pandasよりも格段に速いデータ処理が可能です。特に大きなデータではその差が顕著になります。
- メモリ効率の良さ: データを効率的に格納し、不必要なコピーを避けることで、メモリ使用量を抑えることができます。これは、限られたリソースで大規模データを扱う際に非常に重要です。
- 直感的なAPI: Pandasユーザーであれば馴染みやすい、チェーン可能なメソッドを用いたAPI設計になっています。複雑な処理も読みやすく記述できるのが特徴です。
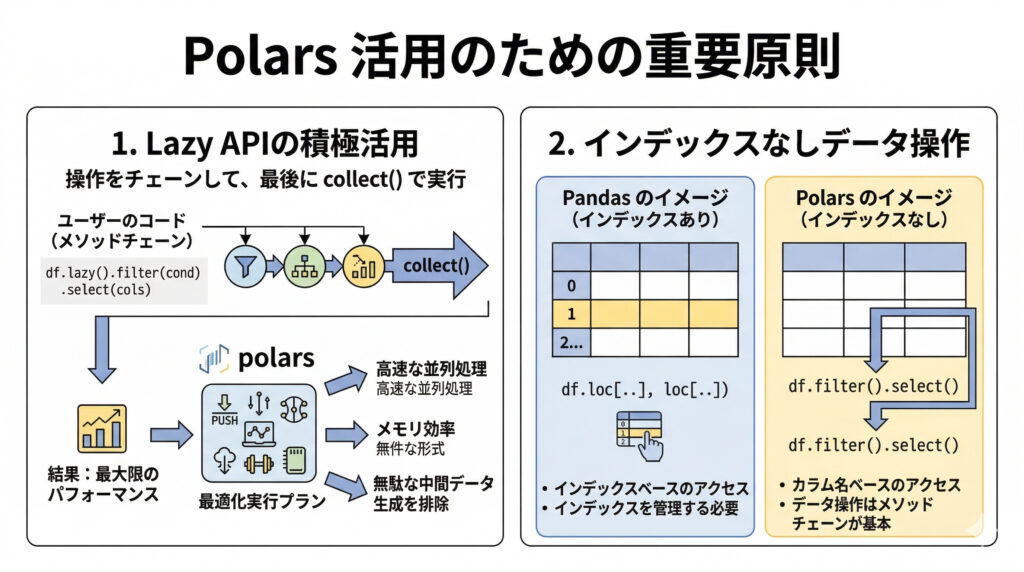
- Lazy Evaluationによる最適化: クエリを即座に実行せず、一連の操作をまとめてから最適化されたプランで実行します。これにより、不要な中間処理がスキップされ、全体として効率的な処理が実現されます。
これで大規模データの処理も怖くありませんね!
サンプルコード
それでは、Polarsの基本的な使い方をいくつか見ていきましょう。
import polars as pl
import pandas as pd
import numpy as np
# 1. データフレームの作成
# Pandasライクに辞書から作成
data = {
'名前': ['Alice', 'Bob', 'Charlie', 'David'],
'年齢': [24, 30, 22, 28],
'都市': ['Tokyo', 'Osaka', 'Tokyo', 'Nagoya'],
'スコア': [85, 92, 78, 95]
}
df = pl.DataFrame(data)
print("--- 1. データフレームの作成 ---")
print(df)
print("\n")
# 2. CSVファイルの読み込み (例としてPandasでCSVを作成)
# df_pd = pd.DataFrame(data)
# df_pd.to_csv("sample_data.csv", index=False)
# df_csv = pl.read_csv("sample_data.csv")
# print("--- 2. CSVファイルの読み込み ---")
# print(df_csv)
# print("\n")
# より大規模なダミーデータを作成 (Polarsの強みがわかるように)
n_rows = 1_000_000
large_data = {
'id': np.arange(n_rows),
'category': np.random.choice(['A', 'B', 'C'], n_rows),
'value1': np.random.rand(n_rows) * 100,
'value2': np.random.randint(0, 1000, n_rows)
}
large_df = pl.DataFrame(large_data)
print("--- 大規模データフレームの一部 ---")
print(large_df.head())
print("\n")
# 3. データの選択 (select)
# 複数の列を選択
selected_df = large_df.select(['id', 'category'])
print("--- 3. データの選択 (idとcategory列) ---")
print(selected_df.head())
print("\n")
# 4. データのフィルタリング (filter)
# categoryが'A'の行とvalue1が50以上の行をフィルタリング
filtered_df = large_df.filter(
(pl.col('category') == 'A') & (pl.col('value1') >= 50)
)
print("--- 4. データのフィルタリング (category='A' & value1>=50) ---")
print(filtered_df.head())
print("\n")
# 5. 列の追加・変換 (with_columns)
# value3という新しい列を、value1とvalue2の合計として追加
transformed_df = large_df.with_columns(
(pl.col('value1') + pl.col('value2')).alias('value3')
)
print("--- 5. 列の追加・変換 (value3 = value1 + value2) ---")
print(transformed_df.head())
print("\n")
# 6. グループ化と集計 (group_by)
# categoryごとにvalue1の平均とvalue2の最大値を計算
grouped_df = large_df.group_by('category').agg(
pl.col('value1').mean().alias('avg_value1'),
pl.col('value2').max().alias('max_value2')
).sort('category') # 結果を見やすくするためにソート
print("--- 6. グループ化と集計 (categoryごとの平均・最大値) ---")
print(grouped_df)
print("\n")
# 7. LazyFrameを使った遅延評価
このLazyFrameこそが、Polarsの真骨頂なんです!
# `collect()`で初めて実行されます。
lazy_df = large_df.lazy().filter(
pl.col('value1') > 90
).group_by('category').agg(
pl.col('value2').mean().alias('mean_high_value2')
).sort('category')
print("--- 7. LazyFrame (実行計画のみ表示) ---")
print(lazy_df.explain()) # 実行計画を表示
print("\n")
print("--- 7. LazyFrame (collect()で実行) ---")
result_df = lazy_df.collect()
print(result_df)
print("\n")みーちゃんのワンポイント
Polarsを使う上で最も大切なのは、「LazyFrame」を積極的に活用し、最後にcollect()で実行することです。これにより、Polarsが最適な実行プランを立ててくれるため、パフォーマンスが最大限に引き出されます。また、PolarsにはPandasのようなインデックスの概念がないので、データ操作はメソッドチェーンで行うのが基本ですよ。