Pythonで時間のかかる計算処理や、多くのタスクを同時にこなしたいと考えたことはありませんか?Pythonはコードの記述がシンプルで分かりやすい一方で、処理速度が課題となる場面も少なくありません。特に、CPUをたくさん使うような「計算集約型」の処理では、その特性から最大限のパフォーマンスを発揮しづらいことがあります。
普段使っているPCのCPUには、複数のコアが搭載されていますよね。それをPythonでも活用しちゃいましょう!
multiprocessingとは?
multiprocessingは、Pythonで並列処理を実現するための標準ライブラリです。一般的なPythonプログラムは、「GIL(Global Interpreter Lock)」という仕組みによって、一度に一つのスレッドしかCPUの計算資源を使えない制約があります。しかし、multiprocessingは「プロセス」というOSが管理する独立した実行単位を複数生成することで、このGILの制約を回避し、複数のCPUコアを同時に利用した真の並列処理を可能にします。
メリット
multiprocessingを活用することには、いくつかの大きなメリットがあります。
- 計算集約型処理の高速化: 大量のデータ処理や複雑な計算など、CPUを長時間占有する処理を複数のプロセスに分割して同時に実行することで、全体の実行時間を大幅に短縮できます。
- プログラムの応答性向上: バックグラウンドで重い処理を実行している間も、メインのプログラム(例えばGUIアプリケーションなど)がフリーズすることなく、ユーザーからの操作に応答し続けることができます。
- 既存のPythonコードとの互換性: 新しい並列処理の概念を学ぶ必要はありますが、既存の関数やクラスをほとんど変更することなく、並列処理の恩恵を受けられます。
サンプルコード
それでは、実際にmultiprocessingを使って処理を高速化する例を見てみましょう。ここでは、時間のかかる計算タスクを定義し、それを逐次処理した場合と、multiprocessing.Poolを使って並列処理した場合で、実行時間を比較します。
import multiprocessing
import time
import os
def long_running_task(n):
"""
時間のかかる計算を模倣する関数
ここでは、nまでの数の二乗和を計算しています。
"""
_ = sum(i * i for i in range(n))
return f"タスク {n} の計算が完了しました。"
if __name__ == "__main__":
# 実行するタスクのリスト(ここでは4つの重いタスクを想定)
inputs = [10**7, 10**7, 10**7, 10**7]
print("--- 通常の逐次処理の場合 ---")
start_time_sequential = time.time()
results_sequential = []
for num in inputs:
results_sequential.append(long_running_task(num))
end_time_sequential = time.time()
print("結果:", results_sequential)
print(f"逐次処理にかかった時間: {end_time_sequential - start_time_sequential:.2f}秒\n")
print("--- multiprocessing.Pool を使った並列処理の場合 ---")
# 利用可能なCPUコア数を取得し、それに応じたプロセス数を設定します。
# ここでは、PCのコア数と同じ数のプロセスを生成します。
num_processes = os.cpu_count()
if num_processes is None:
num_processes = 4 # 取得できない場合のデフォルト値
start_time_parallel = time.time()
# Poolを使って複数のプロセスにタスクを割り当て、並列実行します
with multiprocessing.Pool(processes=num_processes) as pool:
# map関数は、リストの各要素に関数を適用し、結果を返します
results_parallel = pool.map(long_running_task, inputs)
end_time_parallel = time.time()
print("結果:", results_parallel)
print(f"並列処理にかかった時間: {end_time_parallel - start_time_parallel:.2f}秒")
print(f"\n並列処理は逐次処理より {(end_time_sequential - start_time_sequential) / (end_time_parallel - start_time_parallel):.1f} 倍速くなりました!")このコードを実行すると、multiprocessingを使った並列処理が、いかに高速であるかを実感できるはずです。私の環境では、同じタスクでも並列処理の方が数倍速く終わりましたよ!
ぜひ皆さんのPCで試して、その速さを体験してみてくださいね!
みーちゃんのワンポイント
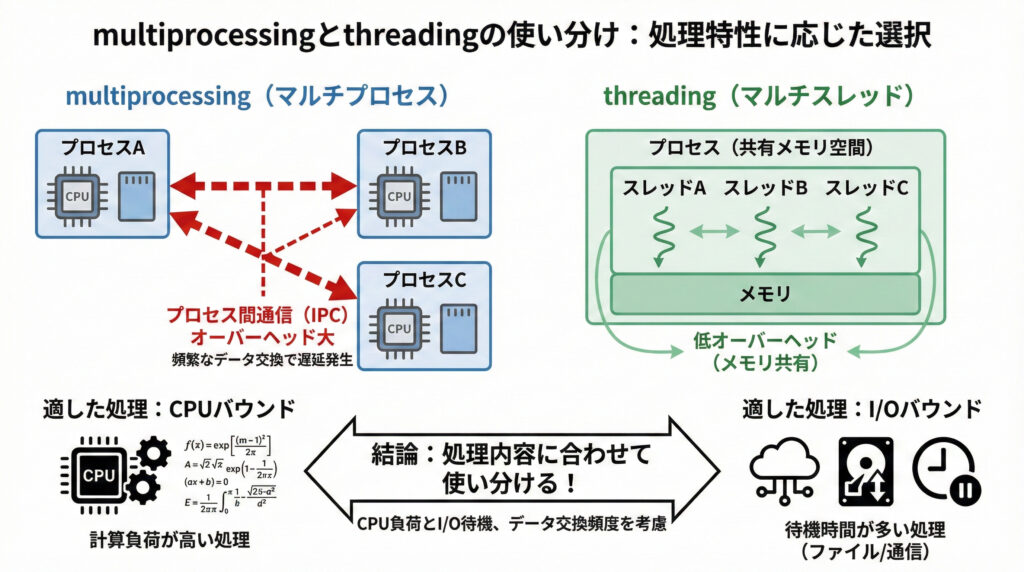
multiprocessingはパワフルですが、プロセス間の通信にはオーバーヘッドがあることを意識してください。頻繁なデータ交換が必要な処理では、かえって遅くなることもあります。また、I/Oバウンド(ファイル読み書きやネットワーク通信待ちが多い)な処理には、threadingライブラリの方が適している場合もありますので、処理内容に合わせて使い分けが大切です!