プログラミングをしていると、時々「もっと効率的に処理を進めたいな」と思うことはありませんか?例えば、時間のかかるデータ処理中にユーザーインターフェースが固まってしまったり、複数のファイルを同時にダウンロードできたら便利なのに、と感じたり……。
Pythonのthreadingライブラリは、そんな願いを叶えるための強力なツールです。これは、プログラム内で複数のタスクを「並行して」実行するための機能を提供します。まるで、私たちが宿題と読書を同時に進めるように、プログラムも複数の処理を効率良く進められるようになるのです。
概要
threadingライブラリは、Pythonで「スレッド」と呼ばれる小さな実行単位を扱うための機能を提供します。スレッドは、同じプロセス内でメモリ空間を共有しながら、独立した処理の流れを実行します。
基本的な使い方としては、主に以下のステップでスレッドを操作します。
- スレッドの作成:
threading.Threadクラスのインスタンスを作成します。このとき、target引数にスレッドとして実行したい関数を指定し、args引数にその関数に渡す引数をタプルで指定します。 - スレッドの開始: 作成したスレッドオブジェクトの
start()メソッドを呼び出すことで、スレッドの実行を開始します。 - スレッドの終了待ち:
join()メソッドを呼び出すことで、メインスレッド(プログラムの主たる実行の流れ)が対象のスレッドの終了を待つことができます。これにより、全てのスレッドが完了した後に次の処理に進む、といった制御が可能になります。
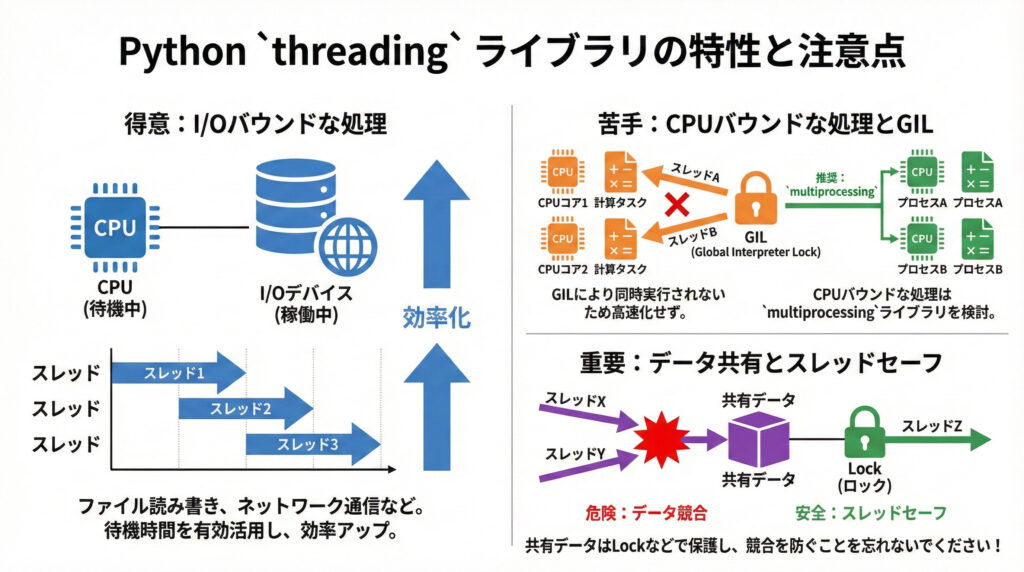
また、複数のスレッドが同じデータに同時にアクセスすると、予期せぬ結果を引き起こすことがあります(これを「競合状態(レースコンディション)」と呼びます)。これを防ぐために、threadingライブラリはLockオブジェクトを使った「排他制御」の機能も提供しています。これにより、一度に一つのスレッドだけが共有データにアクセスできるようになり、データの整合性が保たれます。
スレッドは同じメモリを共有するから、データの扱いには特に注意が必要なんです。
メリット
threadingライブラリを活用することで、次のようなメリットが得られます。
- プログラムの応答性向上: 時間のかかる処理(例:ファイルのダウンロード、複雑な計算など)をバックグラウンドのスレッドで実行し、その間にメインスレッドでユーザーインターフェースの更新や他の短い処理を行うことができます。これにより、プログラムが「固まった」ように見えることを防ぎ、ユーザー体験を向上させます。
- I/O処理の効率化: ネットワーク通信やファイルI/Oなど、外部とのやり取りで「待ち時間」が発生する処理を並行して行うことで、全体の実行時間を大幅に短縮できます。待機中に別のスレッドが作業を進めることができるため、システムリソースを有効活用できます。
- 並行タスクの管理: 複数の独立したタスクを同時に実行したい場合に、それぞれをスレッドとして定義し管理することで、プログラムの構造をシンプルに保ちつつ、効率的な実行を実現できます。
サンプルコード
それでは、実際にthreadingを使ってみましょう。
1. 基本的なスレッドの実行
複数のタスクを並行して実行するシンプルな例です。
import threading
import time
def task(name):
"""スレッドとして実行するタスクの例"""
print(f"スレッド {name}: 開始しますね!")
time.sleep(2) # 2秒間待機(何かの処理をシミュレート)
print(f"スレッド {name}: 終了しました。")
print("メインスレッド: 2つのスレッドを開始しますね。")
# Threadオブジェクトを作成。targetに関数、argsに引数を指定します。
thread1 = threading.Thread(target=task, args=("タスクA",))
thread2 = threading.Thread(target=task, args=("タスクB",))
# スレッドの実行を開始
thread1.start()
thread2.start()
# 各スレッドの終了を待ちます
thread1.join()
thread2.join()
print("メインスレッド: 全てのスレッドが終了しました。")2. Lockを使った排他制御
複数のスレッドが共通の変数にアクセスし、それを安全に更新する例です。Lockを使わないと、最終的な値が期待通りにならないことがあります。
import threading
import time
shared_counter = 0 # 複数のスレッドで共有するカウンター
counter_lock = threading.Lock() # Lockオブジェクトを生成します
def increment_counter():
"""カウンターをインクリメントするタスク"""
global shared_counter
for _ in range(100000): # 10万回インクリメント
# Lockを使って排他制御を行います
# with文を使うと、Lockの取得と解放が自動的に行われます
with counter_lock:
shared_counter += 1
print("メインスレッド: 複数のスレッドでカウンターをインクリメントします。")
threads = []
for i in range(5): # 5つのスレッドを作成
thread = threading.Thread(target=increment_counter)
threads.append(thread)
thread.start()
# 全てのスレッドの終了を待ちます
for thread in threads:
thread.join()
# 最終的なカウンターの値を出力(期待値は50万)
print(f"最終的なカウンターの値: {shared_counter}")Lockを使うことで、共有変数を安全に扱えるようになりますよ!
みーちゃんのワンポイント
Pythonのthreadingは、「I/Oバウンドな処理」で特にその真価を発揮します。ファイル読み書きやネットワーク通信のように、CPUが処理を待つ時間が長いタスクでは、並行処理で効率アップが見込めます。
一方、PythonにはGIL(Global Interpreter Lock)という仕組みがあるため、純粋なCPU計算(「CPUバウンドな処理」)を複数のスレッドで並行しても、同時に実行されるわけではありません。そのため、CPUバウンドな処理を高速化したい場合は、multiprocessingライブラリの利用を検討してくださいね。
スレッド間で共有するデータは、必ずLockなどを使ってスレッドセーフに保つことを忘れないでください!