機械学習に興味があるけれど、どこから始めればいいか分からない…という方もいらっしゃるかもしれませんね。Pythonには強力な機械学習ライブラリ「scikit-learn」があります。このライブラリを使えば、驚くほど簡単に高度な分析が可能になります。今回は、そんなscikit-learnの魅力と基本的な使い方をご紹介します。
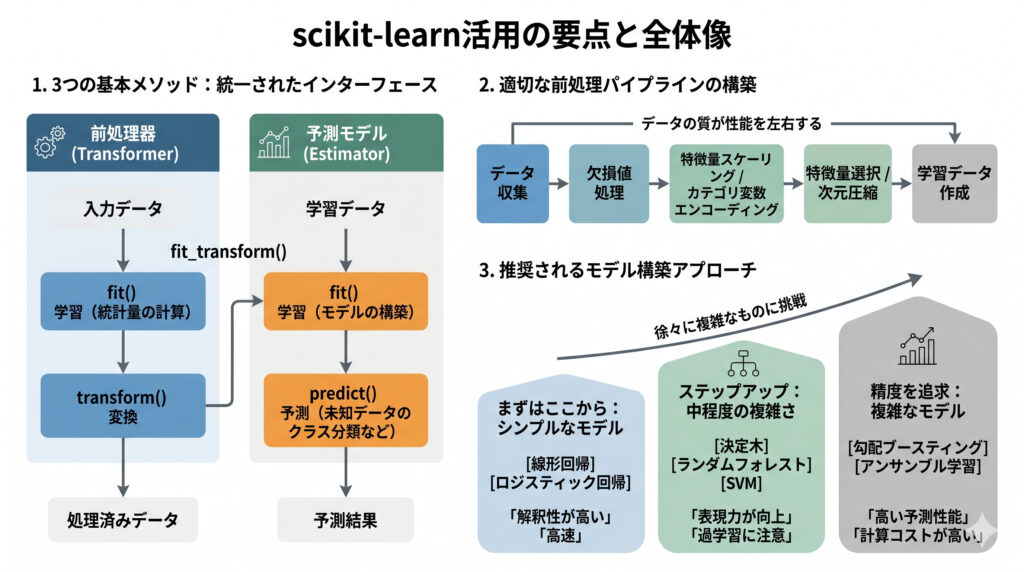
scikit-learnの統一されたAPIは、本当に使いやすくて感動しちゃいますよね!
概要
scikit-learnは、Pythonで実装されたオープンソースの機械学習ライブラリです。分類、回帰、クラスタリング、次元削減、モデル選択、前処理など、幅広い機械学習アルゴリズムとツールを提供しています。その最大の特徴は、アルゴリズムの種類にかかわらず、データの前処理からモデルの学習、予測までを統一されたAPIインターフェースで行える点です。NumPy、SciPy、Matplotlibといった他の科学計算ライブラリと連携しやすく、Pythonのデータ分析エコシステムの中核を担う存在となっています。
メリット
scikit-learnには、機械学習を始める方からプロフェッショナルまで、多くのユーザーに選ばれる理由がたくさんあります。
- 手軽に利用可能: 豊富なアルゴリズムが実装されており、数行のコードで高度な機械学習モデルを構築できます。複雑な数学的背景を深く理解していなくても、まずはモデルを動かしてみることができます。
- 統一されたAPI:
fit(),predict(),transform()といった共通のメソッドで様々なモデルを扱えるため、一度使い方を覚えれば他のアルゴリズムへの応用も簡単で、学習コストが低いです。 - 高い信頼性: 長年の開発と世界中の多くのユーザーによる利用・貢献によって、その安定性と信頼性が確立されています。
- 充実したドキュメント: 公式ドキュメントが非常に詳細で分かりやすく、使用例も豊富に記載されているため、学習の大きな助けとなります。
- 豊富な機能: データの前処理(標準化、欠損値補完など)からモデルの評価(精度指標、交差検定など)まで、機械学習のワークフロー全体をサポートするツールが揃っています。
サンプルコード
それでは、scikit-learnを使って実際に簡単な分類モデルを構築してみましょう。今回は、機械学習のチュートリアルでよく使われる「Irisデータセット」を用いて、花の品種を予測する決定木モデルを作成します。
pip install scikit-learn# 必要なライブラリをインポートします
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# Irisデータセットをロードします
# このデータセットには、3種類のIrisの花の「がく片と花弁の長さと幅」が記録されています。
iris = load_iris()
X = iris.data # 特徴量(がく片と花弁の長さ・幅)
y = iris.target # 目的変数(花の品種:0, 1, 2)
# データを訓練用とテスト用に分割します
# test_size=0.2 で、全データの20%をテストデータとします。
# random_state で乱数のシードを固定することで、毎回同じ分割結果が得られます。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 決定木分類器のインスタンスを作成します
# ここでも random_state を設定し、再現性を確保します。
model = DecisionTreeClassifier(random_state=42)
# 訓練データを使ってモデルを学習させます(fitメソッド)
# この段階でモデルがデータからパターンを学びます。
print("モデルの学習を開始します...")
model.fit(X_train, y_train)
print("モデルの学習が完了しました!")
# テストデータを使って予測を行います(predictメソッド)
# 学習済みのモデルが、未知のデータに対してどのような予測をするかを見ます。
y_pred = model.predict(X_test)
# モデルの性能を評価します(正解率を計算)
# 予測結果と実際の値がどれくらい一致しているかを確認します。
accuracy = accuracy_score(y_test, y_pred)
print(f"モデルの正解率: {accuracy:.2f}")
# 簡単な予測例
# 例えば、特徴量が [5.0, 3.5, 1.3, 0.2] の花の種類を予測してみましょう。
# これは 'setosa' という品種の特徴量に近い値です。
sample_data = [[5.0, 3.5, 1.3, 0.2]]
predicted_species_index = model.predict(sample_data)[0]
# 予測された数値インデックスを、実際の品種名に変換します。
predicted_species_name = iris.target_names[predicted_species_index]
print(f"\n入力データ {sample_data} の予測結果: {predicted_species_name}")モデルの学習を開始します...
モデルの学習が完了しました!
モデルの正解率: 1.00
入力データ [[5.0, 3.5, 1.3, 0.2]] の予測結果: setosaこのコードでは、Irisデータセットを読み込み、訓練データとテストデータに分割した後、決定木モデルを学習させ、その性能を評価しています。最後に、新しいデータに対する予測も行ってみました。
コードは短いですが、これだけで本格的な予測モデルが作れちゃうんです!すごいでしょう?
みーちゃんのワンポイント
scikit-learnを使いこなす上で最も重要なのは、なんといってもfit(), predict(), transform()の3つのメソッドが基本であることを理解することです。ほとんどのモデルや前処理器でこれらの統一されたインターフェースが使われます。また、機械学習モデルの性能はデータの質に大きく左右されるため、適切な前処理パイプラインを構築することも非常に大切です。まずはシンプルなモデルから始めて、少しずつ複雑なものに挑戦していくのがおすすめです。