私は日頃から、Pythonのコードをもっと綺麗に、もっと効率的に書きたいと考えています。そんな時、標準ライブラリの中に隠れた宝石のようなモジュールを見つけました。それが今回ご紹介するcollectionsです。普段使っているリストや辞書、タプルをさらに便利にしてくれる、とっても素敵なツールなんですよ。
概要
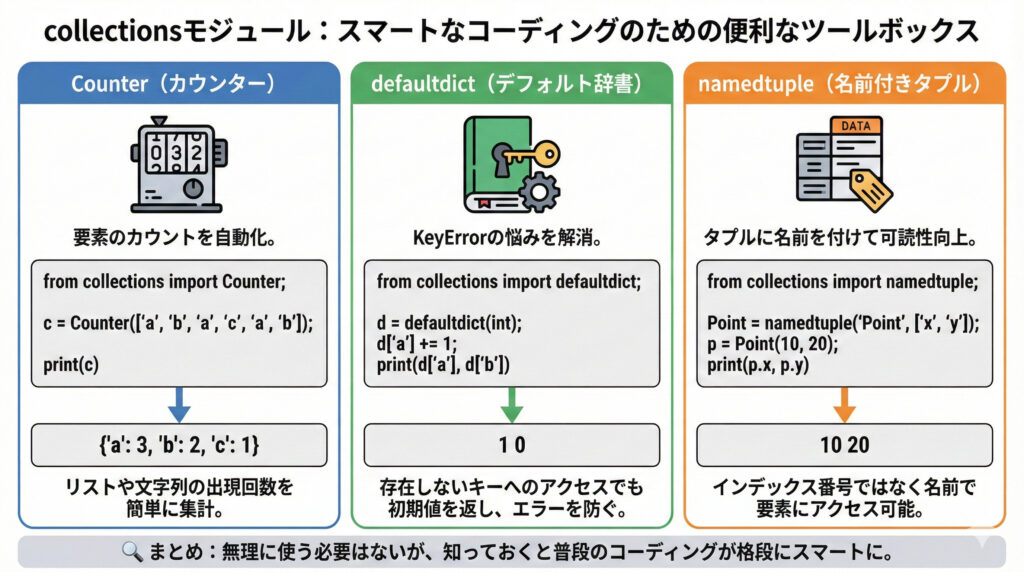
Pythonのcollectionsモジュールは、一般的なデータ型(リスト、辞書、タプルなど)を拡張し、特定の用途に特化した高機能なデータ構造を提供する標準ライブラリです。これを使うことで、複雑な処理をより簡潔に、そしてPythonicに記述できるようになります。
たとえば、要素の出現回数を数えたり、辞書にキーが存在しない場合の挙動をカスタマイズしたり、構造体のように名前でアクセスできるタプルを作成したりする機能が提供されています。
メリット
collectionsを使うことで、次のようなメリットがあります。
- コードの可読性向上:
namedtupleを使えば、インデックスではなく名前で要素にアクセスできるようになり、コードが何を意味しているのか一目でわかるようになります。 - 処理の効率化:
Counterは要素の集計を非常に効率的に行い、手動でループを回してカウントするよりも高速です。また、dequeはリストの先頭・末尾での追加・削除操作を高速化します。 - 簡潔なコード記述:
defaultdictを使えば、辞書にキーが存在しない場合の初期化処理を大幅に簡略化でき、多くのif文を削減できます。 - エラーの削減:
defaultdictはKeyErrorの発生を防ぎ、より堅牢なコードになります。
これらのメリットは、プログラムの保守性を高め、開発効率を向上させることにも繋がります。
サンプルコード
それでは、collectionsモジュールから特に利用頻度の高いCounter、defaultdict、namedtupleの3つを例に、具体的な使い方を見ていきましょう。
1. Counter: 要素の出現回数を数える
Counterは、ハッシュ可能なオブジェクトのコレクションから、それぞれの要素が何回出現したかを数えるのに特化した辞書のようなオブジェクトです。
from collections import Counter
# 文字列の各文字の出現回数をカウント
text = "hello python programming"
char_counts = Counter(text)
print("文字の出現回数:", char_counts)
# 出力例: 文字の出現回数: Counter({'o': 4, 'g': 3, 'r': 3, 'm': 2, 'h': 2, 'p': 2, 'n': 2, 'e': 1, 'l': 1, 't': 1, 'a': 1, 'i': 1, ' ': 1})
# リスト内の要素の出現回数をカウント
fruits = ["apple", "banana", "apple", "orange", "banana", "apple"]
fruit_counts = Counter(fruits)
print("果物の出現回数:", fruit_counts)
# 出力例: 果物の出現回数: Counter({'apple': 3, 'banana': 2, 'orange': 1})
# 最も出現回数の多い要素をN個取得
most_common_fruits = fruit_counts.most_common(2)
print("最も多い果物トップ2:", most_common_fruits)
# 出力例: 最も多い果物トップ2: [('apple', 3), ('banana', 2)]データ分析やログ解析で、頻出する単語を調べたい時などに大活躍しますよ!
2. defaultdict: 辞書にキーが存在しない場合のデフォルト値を設定
通常の辞書では、存在しないキーにアクセスしようとするとKeyErrorが発生します。defaultdictは、キーが存在しない場合に自動的にデフォルト値を生成して返す、拡張された辞書です。
from collections import defaultdict
# 値がリストになるdefaultdict
# キーが存在しない場合、空のリストが自動的に作成されます
grouped_items = defaultdict(list)
data = [
("apple", "red"),
("banana", "yellow"),
("grape", "purple"),
("apple", "green"),
("banana", "green")
]
for item, color in data:
grouped_items[item].append(color)
print("グループ分けされたアイテム:", grouped_items)
# 出力例: グループ分けされたアイテム: defaultdict(<class 'list'>, {'apple': ['red', 'green'], 'banana': ['yellow', 'green'], 'grape': ['purple']})
# 値が整数のdefaultdict
# キーが存在しない場合、0が自動的に作成されます (int()は0を返すため)
counts = defaultdict(int)
words = ["hello", "world", "hello", "python"]
for word in words:
counts[word] += 1
print("単語のカウント:", counts)
# 出力例: 単語のカウント: defaultdict(<class 'int'>, {'hello': 2, 'world': 1, 'python': 1})3. namedtuple: 名前付きタプルで可読性アップ
namedtupleは、通常のタプルと同様にイミュータブル(変更不可能)ですが、要素に名前を付けてアクセスできるようにします。これにより、コードの可読性が格段に向上し、まるで構造体のようにデータを扱えます。
from collections import namedtuple
# 'Point'という名前のnamedtupleを定義
# xとyというフィールド名を持つ
Point = namedtuple("Point", ["x", "y"])
# Pointオブジェクトの作成
p1 = Point(10, 20)
p2 = Point(y=30, x=40)
# 名前で要素にアクセス
print("p1のx座標:", p1.x)
print("p2のy座標:", p2.y)
# 出力例:
# p1のx座標: 10
# p2のy座標: 30
# インデックスでもアクセス可能
print("p1の最初の要素:", p1[0])
# 出力例: p1の最初の要素: 10
# namedtupleはタプルなので、イミュータブル
try:
p1.x = 15 # エラーが発生します
except AttributeError as e:
print("エラー:", e)
# 出力例: エラー: can't set attribute
# リストのように複数のnamedtupleを扱うこともできます
Circle = namedtuple("Circle", ["center", "radius"])
c1 = Circle(Point(0, 0), 5)
c2 = Circle(Point(10, 10), 8)
circles = [c1, c2]
for circle in circles:
print(f"中心: ({circle.center.x}, {circle.center.y}), 半径: {circle.radius}")
# 出力例:
# 中心: (0, 0), 半径: 5
# 中心: (10, 10), 半径: 8普通のタプルだと何のデータか分かりにくい時でも、namedtupleならコードがぐっと分かりやすくなります!
みーちゃんのワンポイント
collectionsモジュールは、まさに「痒い所に手が届く」ような便利なツールが集まっています。無理に使う必要はありませんが、Counterやdefaultdict、namedtupleは、知っておくと普段のコーディングが格段にスマートになりますよ。特にKeyErrorで悩まされがちな方は、ぜひdefaultdictを試してみてくださいね!