データ分析の重要性が高まる現代において、Pythonは非常に強力なツールとして認識されています。その中でも、特にデータ操作と分析においてデファクトスタンダードとなっているのが、今回ご紹介するライブラリ「pandas」です。私と一緒に、pandasの魅力と使い方を学んで、データ分析のスキルを一段と高めていきましょう。
pandasは、表計算ソフトでは難しいような大量のデータや複雑な操作も、コードでサッと処理できるのが本当に便利なんです!
概要
pandasは、Pythonでデータ分析を行うためのオープンソースライブラリです。主に表形式データ(Excelのシートやデータベースのテーブルのような形式)を効率的に扱うために設計されており、R言語のデータフレームに近い機能を提供します。
主要なデータ構造として、以下の二つがあります。
- Series(シリーズ): 1次元の配列のようなデータ構造で、インデックス(ラベル)を持ちます。Excelの1列をイメージすると分かりやすいかもしれません。
- DataFrame(データフレーム): 2次元の表形式データ構造で、複数のSeriesを組み合わせたものです。行と列にそれぞれインデックス(ラベル)を持ち、異なる型のデータを格納できます。
メリット
pandasがデータ分析の現場でこれほどまでに広く利用されているのには、いくつかの明確なメリットがあります。
- 強力なデータ操作機能: データのフィルタリング、ソート、集計、結合、整形といった、あらゆる種類のデータ操作を直感的かつ効率的に行うことができます。
- 欠損値処理の容易さ: データにはよく欠損値(NAやNaN)が含まれていますが、pandasはこれらの欠損値を検出、削除、補完するための豊富な機能を提供します。
- 多様なファイル形式のサポート: CSV、Excel、JSON、SQLデータベースなど、様々な形式のデータを簡単に読み込み・書き出すことができます。
- 高いパフォーマンス: 内部的には数値計算に特化したライブラリNumPyを基盤としているため、大規模なデータセットに対しても高速な処理が可能です。
- 豊富な分析機能: グループ化による集計(groupby)、ピボットテーブルの作成、時系列データ分析など、高度な分析機能が組み込まれています。
サンプルコード
それでは、実際にpandasを使って基本的なデータ操作を行ってみましょう。ここでは、簡単なDataFrameの作成から、CSVファイルの読み込み、データ選択、フィルタリング、そして基本的な集計までの一連の流れをご紹介します。
import pandas as pd
import numpy as np
# 1. DataFrameの作成
# ディクショナリからDataFrameを作成します
data = {
'名前': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'年齢': [25, 30, np.nan, 22, 28], # np.nanで欠損値を表現
'都市': ['Tokyo', 'Osaka', 'Tokyo', 'Nagoya', 'Kyoto'],
'スコア': [85, 92, 78, 95, 88]
}
df = pd.DataFrame(data)
print("--- 1. 作成したDataFrame ---")
print(df)
print("\n")
# 2. CSVファイルの読み込み (仮のCSVファイルを作成します)
# 実際には pd.read_csv('your_file.csv') のように使います
df.to_csv('sample_data.csv', index=False) # サンプルとしてCSVを書き出し
print("--- 2. CSVファイルから読み込んだDataFrame (最初の5行) ---")
df_from_csv = pd.read_csv('sample_data.csv')
print(df_from_csv.head()) # .head()で最初の数行を表示
print("\n")
# 3. 特定の列を選択
print("--- 3. '名前' 列の選択 ---")
print(df['名前'])
print("\n")
# 4. 複数の列を選択
print("--- 4. '名前' と 'スコア' 列の選択 ---")
print(df[['名前', 'スコア']])
print("\n")
# 5. 条件による行のフィルタリング
print("--- 5. 年齢が25歳以上の行をフィルタリング ---")
print(df[df['年齢'] >= 25])
print("\n")
# 6. 複数の条件によるフィルタリング
print("--- 6. 都市がTokyoでスコアが80以上の行をフィルタリング ---")
print(df[(df['都市'] == 'Tokyo') & (df['スコア'] >= 80)])
print("\n")
# 7. データの集計 (例: 平均年齢を計算)
print("--- 7. 平均年齢の計算 ---")
average_age = df['年齢'].mean()
print(f"平均年齢: {average_age:.2f}歳")
print("\n")
# 8. 欠損値の確認
print("--- 8. 欠損値の有無を確認 ---")
print(df.isnull().sum()) # 各列の欠損値の数を表示
print("\n")
# 9. 欠損値の補完 (例: NaNを平均値で補完)
print("--- 9. 欠損値を平均値で補完した後のDataFrame ---")
df_filled = df.fillna({'年齢': average_age})
print(df_filled)コードブロックがたくさんあって難しそうに見えるかもしれませんが、一つ一つの操作はとてもシンプルなので、ぜひ手を動かして試してみてくださいね!
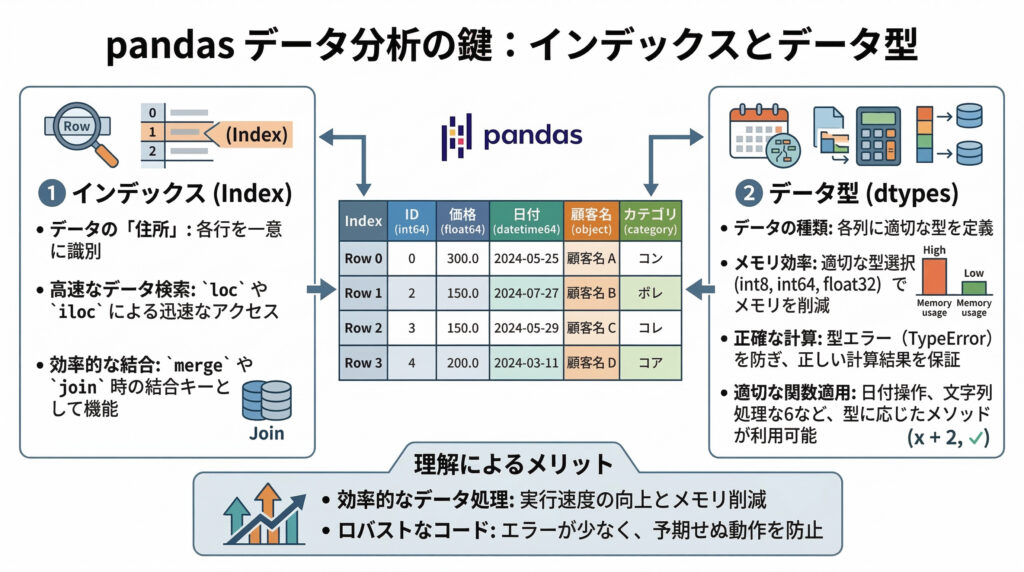
みーちゃんのワンポイント
pandasを使いこなす上で、特に意識してほしいのは「インデックス」と「データ型」です。インデックスはデータの高速な検索や結合に、データ型はメモリ効率や正確な計算に直結します。これらの概念をしっかり理解しておくことで、より効率的でロバストなデータ処理が可能になりますよ。