皆さん、こんにちは!プログラミングが大好きな私がお届けする技術ブログの時間です。今回は、Pythonでデータサイエンスや機械学習を学ぶ上で、避けては通れない非常に重要なライブラリ『numpy』について、分かりやすく解説していきますね。データの扱いに革命をもたらすnumpyの魅力を、ぜひ感じてください!
概要
numpyは、Pythonで多次元配列を効率的に扱うためのライブラリです。その中心となるデータ構造はndarray(N-dimensional array)と呼ばれ、ベクトル、行列、さらにはそれ以上の次元を持つ配列を表現できます。Python標準のリストとは異なり、すべての要素が同じデータ型を持つことが特徴です。これにより、メモリ効率が非常に高く、大量の数値データを高速に処理することが可能になります。
メリット
numpyは、その高いパフォーマンスと豊富な機能により、データサイエンスのあらゆる分野で活用されています。
- 圧倒的な高速性: numpyの内部はC言語などで実装されているため、Pythonのリストを使った同等の処理と比較して、非常に高速な数値計算を実現します。特に大規模なデータセットを扱う際にその差は歴然です。
- 効率的なメモリ利用: `ndarray`は要素のデータ型が統一されているため、メモリを無駄なく利用できます。これにより、少ないメモリでより大きなデータを扱えるようになります。
- 豊富な数学関数: 配列の基本的な操作はもちろんのこと、線形代数、フーリエ変換、乱数生成など、科学技術計算に必要な多岐にわたる数学関数が用意されています。
- データサイエンスの基盤: Pandas, SciPy, scikit-learnといった他の主要なデータサイエンスライブラリの多くが、内部でnumpyの`ndarray`を利用しています。numpyを理解することは、これらのライブラリを深く理解する上での第一歩となります。
サンプルコード
それでは、実際にnumpyを使って多次元配列を操作してみましょう。基本的な配列の作成から、演算、スライシングまでをご紹介します。
Pythonのリストとは一味違う、numpyならではのパワフルな操作感に注目してくださいね!
import numpy as np
# 1. 配列の作成
# Pythonのリストから1次元配列を作成
arr1 = np.array([1, 2, 3, 4, 5])
print("1次元配列:", arr1)
print("データ型:", arr1.dtype) # 要素のデータ型
# Pythonのリストのリストから2次元配列(行列)を作成
arr2 = np.array([[10, 20, 30], [40, 50, 60]])
print("\n2次元配列:\n", arr2)
print("形状 (行, 列):", arr2.shape) # 配列の形状
# 特定の値で初期化された配列の作成
# 全て0の2x3行列
zeros_arr = np.zeros((2, 3))
print("\nゼロ配列 (2x3):\n", zeros_arr)
# 全て1の3x2行列
ones_arr = np.ones((3, 2))
print("\n全要素1の配列 (3x2):\n", ones_arr)
# 指定した範囲の数値で配列を作成 (arange)
range_arr = np.arange(0, 10, 2) # 0から10未満で2刻み
print("\n0から10未満で2刻みの配列:", range_arr)
# 2. 基本的な演算
a = np.array([10, 20, 30])
b = np.array([1, 2, 3])
# 要素ごとの加算
print("\n要素ごとの加算 (a + b):", a + b)
# 要素ごとの乗算
print("要素ごとの乗算 (a * b):", a * b)
# スカラー値との演算(ブロードキャスト)
# 配列のすべての要素に5を加算
print("ブロードキャスト(配列 + スカラー):", a + 5)
# 3. スライシングとインデックス操作
matrix = np.array([[10, 11, 12],
[13, 14, 15],
[16, 17, 18]])
print("\n元の行列:\n", matrix)
# 1行目(インデックス1)の取得
print("1行目(インデックス1):", matrix[1])
# 2列目(すべての行のインデックス1)の取得
print("2列目(すべての行のインデックス1):", matrix[:, 1])
# 部分行列の取得 (1行目から2行目、1列目から2列目)
print("部分行列(1行目から2行目、1列目から2列目):\n", matrix[1:3, 1:3])
# 4. 形状の変更 (reshape)
flat_arr = np.arange(1, 10) # 1から9までの配列
print("\n元のフラットな配列:", flat_arr)
# 1次元配列を3x3の2次元配列に変換
reshaped_arr = flat_arr.reshape(3, 3)
print("3x3にリシェイプ:\n", reshaped_arr)
# -1 を使うと、残りの次元から自動的に計算される
auto_reshaped_arr = flat_arr.reshape(-1, 3) # 3列になるように行数を自動調整
print("-1を使った自動リシェイプ:\n", auto_reshaped_arr)どうですか?直感的に配列を扱えるだけでなく、複雑な操作もたった1行で書けてしまうパワフルさに驚きませんか?
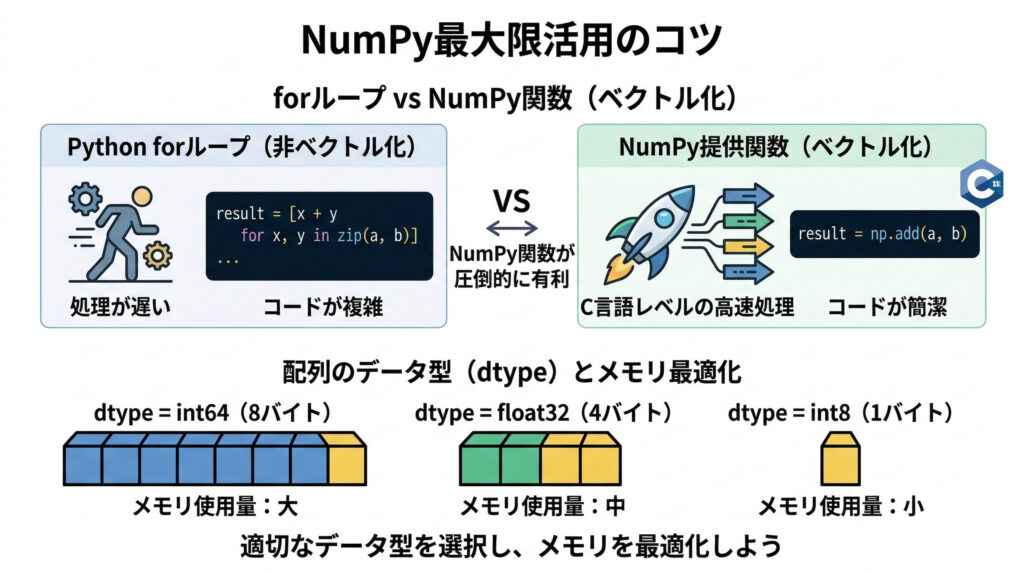
みーちゃんのワンポイント
numpyを最大限に活用するコツは、Pythonのforループを使わず、numpyの提供する関数で処理を完結させる「ベクトル化」です。これにより、C言語レベルの高速な処理が実現され、コードも簡潔になります。また、配列のデータ型(dtype)を意識すると、メモリ使用量を最適化できますよ。